Activity
Mon
Wed
Fri
Sun
Jan
Feb
Mar
Apr
May
Jun
Jul
Aug
Sep
Oct
Nov
Dec
What is this?
Less
More
Memberships
AI Automation Society
208.5k members • Free
Business AI Alliance
8k members • Free
Zero2Launch AI Automation
5.5k members • $1/m
3 contributions to AI Automation Society

Mar 28 •
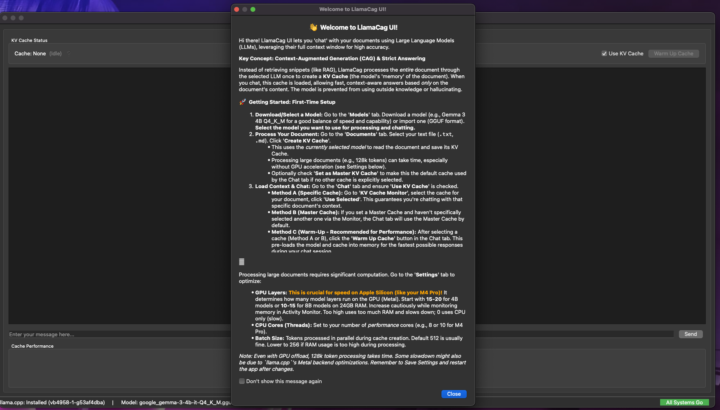
LlamaCag UI. Local CAG: Maximizing Local LLM Performance & Accuracy
After some debugging this is Alpha. Git: https://github.com/AbelCoplet/LlamaCagUI Must Read: https://github.com/AbelCoplet/LlamaCagUI/blob/main/ADDITIONALREADME/llamacag-kv-cache-guide.md **TLDR:** LlamaCag isn't just another document chat app - it's an exploration into Context-Augmented Generation (CAG), a powerful but underutilized approach to working with documents in local LLMs. Unlike mainstream RAG systems that fragment documents into chunks, CAG leverages the full context window by maintaining the model's internal state. What is Context-Augmented Generation? CAG is fundamentally different from how most systems handle documents today: * **RAG** (Retrieval-Augmented Generation): Splits documents into chunks, stores in vector DBs, retrieves relevant chunks for each query * **Manual Insertion**: Directly places document text into each prompt, requiring full reprocessing every time * **CAG**: Processes the document ONCE to populate the model's KV (Key-Value) cache state, then saves and reuses this state Despite its potential advantages, CAG remains largely unexplored outside professional ML engineering circles and specialized enterprise solutions. This project aims to change that. Why CAG Matters for Local LLM Usage The current landscape of local LLM applications mostly ignores this approach, despite several compelling advantages: 1. **Efficiency**: Document is processed once, not repeatedly for each query 2. **Context Integrity**: Maintains the complete document context without fragmentation 3. **Speed**: Dramatically faster responses after initial processing 4. **Privacy**: Fully local operation for sensitive documents 5. **Accuracy**: Higher factual accuracy due to complete contextual understanding For business applications requiring high-precision document analysis (legal, technical, medical), this approach offers a significant advantage that isn't being widely leveraged.
3
0
Mar 21 •
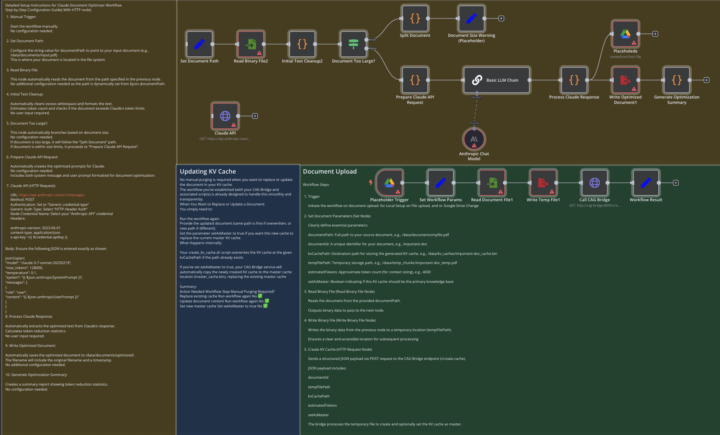
CAG, A Fresh Approach to LLM Document Memory Using 128K Context Windows
Hey everyone, i am a complete novice at this, so be gentle In this project I explore various Memory Management possibilities for local AI, Focusing on CAG. Note i focus on production ready and tangible result rather thatn useless Buzzwords lik AI agents, that are designed to remind you to poop. I'm sharing my project llama-cag-n8n - a complete implementation of Context-Augmented Generation (CAG) for document processing using large context window models. The purpose is to have a reliable LLM to communicate with a fixed dataset with precision. My personal usecase is it has to interact with company handbook and manuals for precise answers to querries. my work is inspired by "dont do RAG" Paper that discusses CAG Wha is CAG (i have explanation on my GIT) The TL;DR: - Instead of chunking documents into tiny pieces like traditional RAG, this system lets models process entire documents at once (up to 128K tokens) - It creates "memory snapshots" (KV caches) of documents that can be instantly loaded for future queries - Much faster responses with deeper document understanding - Works offline, Mac-compatible, and integrates easily via n8n - The Document Processing Sauce Core is the way it handles document preprocessing. I'm using Claude 3.7 Sonnet's 200K input and ability to output exactly 128K tokens to create optimized documents. This sidesteps the need for complex chunking strategies - Claude automatically handles redundancy removal and optimization while preserving all critical information. I mean it is always possible to replace this with a more involved OCR, chunking workflow, but this is not priority for me if i can get away with a more simple solution for now. The workflow: 1. Claude processes the document to fit within the 128K output window 2. The optimized document is sent directly to the KV cache creation process 3. The model's internal state after reading the document is saved as a KV cache This approach is only possible because of Claude's recent capability to produce outputs matching exactly the token limit needed for the KV cache target in its "simple" design
2
0
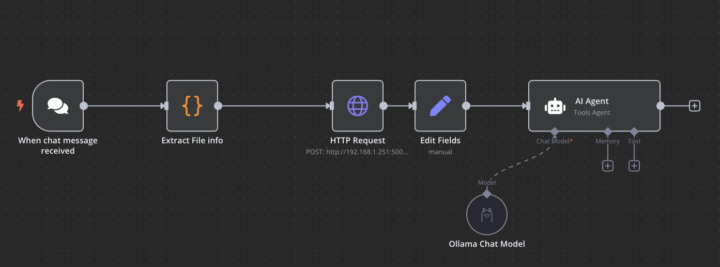
Mar 14 •
Local OCR with Ollama Gemma 3 12b
Hi, new here. following the content closely. EDIT. SOLVED Nevermind, am an idiot, fixed myself, all working correctly. Leaving it up in case it proves useful to anyone i am building a document management system, partially based on RAG template by Cole. one of workflows i need to streamline is fully local OCR. Multiple reasons for that, but one of them is i really like how Gemma 3 model treats the images, and i like the flexibility for doing OCR this way. so with the script i run text extraction from PDFs with gemma 3 locally, and then off it goes to the agent for further processing. i am a bit of a novice, cant figure out what i do wrong. the Edit fields node correctly recieves the text from HTTP request node as input but Agent not seeing the input. i am sorry for noob question, must be something basic i just cant figure out. this is the output from the fields node [ { "extractedText": "{{ $json.extracted_text }}" } ] also if someone has a better setup for local OCR, let me know EDIT: added the following to agent promt {{ $node["Edit Fields"].json.extractedText }}{{ $('HTTP Request').item.json.extracted_text }} now i get correct desired output but what am i doing wrong here. maybe someone with experience can help ? i mean i do get the desired result, but just feels like i am doing something wrong with the set node. Maybe i am missing some edge case scenarios i am not accounting for? i do not necessarily mean the OCR itself, as i have to keep tweaking it for other file type etc, but i mean the framework.
1-3 of 3

@abel-coplet-1817
Learning N8N, business consultant
Active 243d ago
Joined Feb 10, 2025
Powered by