Activity
Mon
Wed
Fri
Sun
Jan
Feb
Mar
Apr
May
Jun
Jul
Aug
Sep
Oct
Nov
What is this?
Less
More
Owned by Jason
For business owners tired of bad devs and useless marketing. Build systems that work and keep the profits where they belong.
Memberships
3 contributions to Systems That Work

3d •
Welcome - Here's What This Place Is About
I started this community because I'm tired of the same story playing out over and over: Business owner needs a system built. Hires a developer or agency. Pays good money. Gets something that half-works or doesn't work at all. Developer disappears or wants more money to "fix" it. Or worse - signs up with a marketing company that charges monthly, promises leads, and can't show a single dollar of ROI after 6 months. I've been on both sides. I've been burned, and I've spent years learning to build my own systems so I don't have to depend on anyone. This community is for people who want to do the same. What you'll find here: - Real talk about what works and what doesn't - Breakdowns of systems I've built (lead gen, voice AI, automation) - Honest reviews of tools and platforms - Help when you're stuck What you won't find: - Courses selling you theory - Gurus who've never built anything - Pitches disguised as "value" If you're here, drop a comment and tell me what you're working on or what problem brought you here. Let's build.
1 like • 24h
@Troy P ah I am always looking for a good wholesale SIP provider. Also, if you have questions about agents or workflows post it. Create a topic, maybe I can help. And I will give you a little secret I learned the hard way to you your point about hand holding devs. If people do not know your industry or how your market operates they cannot build for you. Example...........I had a developer from Siri Lanka write prompts for an American Insurance Brokerage (my own).......how do you think that turned out? First challenge, English was not his first language. Second challenge, he did not know how the American market operates. Third challenge, he had no real world experience in business. And this is what lead me to learn how to prompt line by line.
0 likes • 18h
@Troy P the monitor is from GitHub and monitors the enter system (good Birds Eye view), the simple dashboard is something I’ve been working on.
21h •
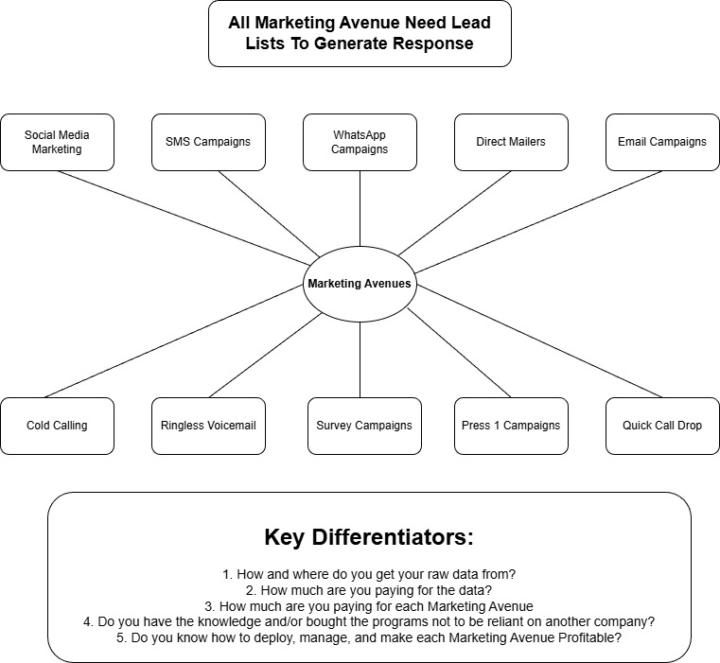
Marketing Avenues (AKA Lead Gen) Every Business Owner Should Know
I might turn this into a class because there is so much to cover in just this one section. I think this is a good place to start and have real honest conversation. For what it is worth I used these methods daily, and know how to deploy each one successfully. Not as a developer, or someone selling something to other business owners; I am speaking as the business owner who developed, manages, and uses these systems.
1
0
3d •
The Real Reason LiveKit Dashboards and DIY Setups Fail
I recently set up a LiveKit dashboard product to manage voice AI agents through a UI. After digging into how it actually works under the hood, I want to share what I found so others can make informed decisions. My Experience After a full day of troubleshooting the backend, the system is still not fully functional. Errors appear throughout the dashboard, and agent creation doesn't work reliably. What struck me most was the resource consumption - 10+ containers just to run a single test agent, and that agent still doesn't work correctly. Why This Architecture Fails for Voice AI When someone calls your business, they expect an immediate greeting. Not 2-5 seconds of silence while processes spawn. The system spawns agents on demand instead of keeping them running. Every layer adds latency. Voice AI should have agents already running and waiting for calls. Other problems I found: - Single point of failure - one container runs everything - No process management - no health checks, no automatic restarts - Resource contention - all agents share the same memory and CPU - Dynamic code generation - agents created on the fly with no version control - Registry dependency - if the developer's server goes down, you can't rebuild What Actually Works I run a production voice AI system that handles real calls for my business. The key differences: - Persistent processes - agents stay running, handle many calls - Proper process management - automatic restarts, monitoring, per-agent logs - Pre-loaded dependencies - everything initialized at startup, not per-call - Independent agents - one agent's issues don't affect others - Direct control - I own all the code, no external dependency My agents answer immediately because they're already running and waiting. Credit Where It's Due The developer was responsive and helped troubleshoot. The UI shows real effort, and the concept is appealing. But building production voice AI requires more than coding skills. Understanding how real-time systems function under load, how processes should be managed, and what architecture choices impact latency - these come from experience. A good idea isn't enough if the foundation doesn't support the use case.
5
0
1-3 of 3

@jason-orloff-3453
Building business systems that actually work. Tired of all the fakeness and zero-ROI marketing? Same here.
Active 2h ago
Joined Dec 4, 2025
Brooklyn, New York